Over the last ten years, we’ve been recording which websites run on green power on the internet. We’ve tracked this, and its changed, to create a database about how we power the web, to provide an open dataset to for data-informed discussion about how we want the web to be powered
In this post, we share an idea we’re working on, that totally inverts this model.
Where we are now
Currently, the sad default for powering the web is to use fossil fuels – so just by using the web, we often end up unintentionally causing harm, and harm that can be avoided by using greener options for powering our infrastructure
This is part of the thinking behind the Sustainable Web Manifesto , which we are signatories of – when it comes to options available to respond to climate, it’s one of the easier ones available to your organisation.

What we mean when we say greener options
We say greener options because if you’ve spent any time looking at the power sector, then you’ll know how complicated it can get – to the extent that something that sounds fairly simple, like sourcing green power to run servers, can end up being much complex than it sounds.
While in some parts of the world, you can buy power from a company that only sells renewable power, there are other parts of the world where the grid is regulated to the point that you don’t even have choice of supplier – if they burn coal, and you need to run a server in that part of the world, there’s no other option.
Elsewhere, there may be places where company A sells renewable power, but also sells the fact that energy has been generated with renewable power separately, so that another company B, can buy this credit, and then say they use green power, even if the supplier they use is relying on fossil fuels to generate electricity for their servers .
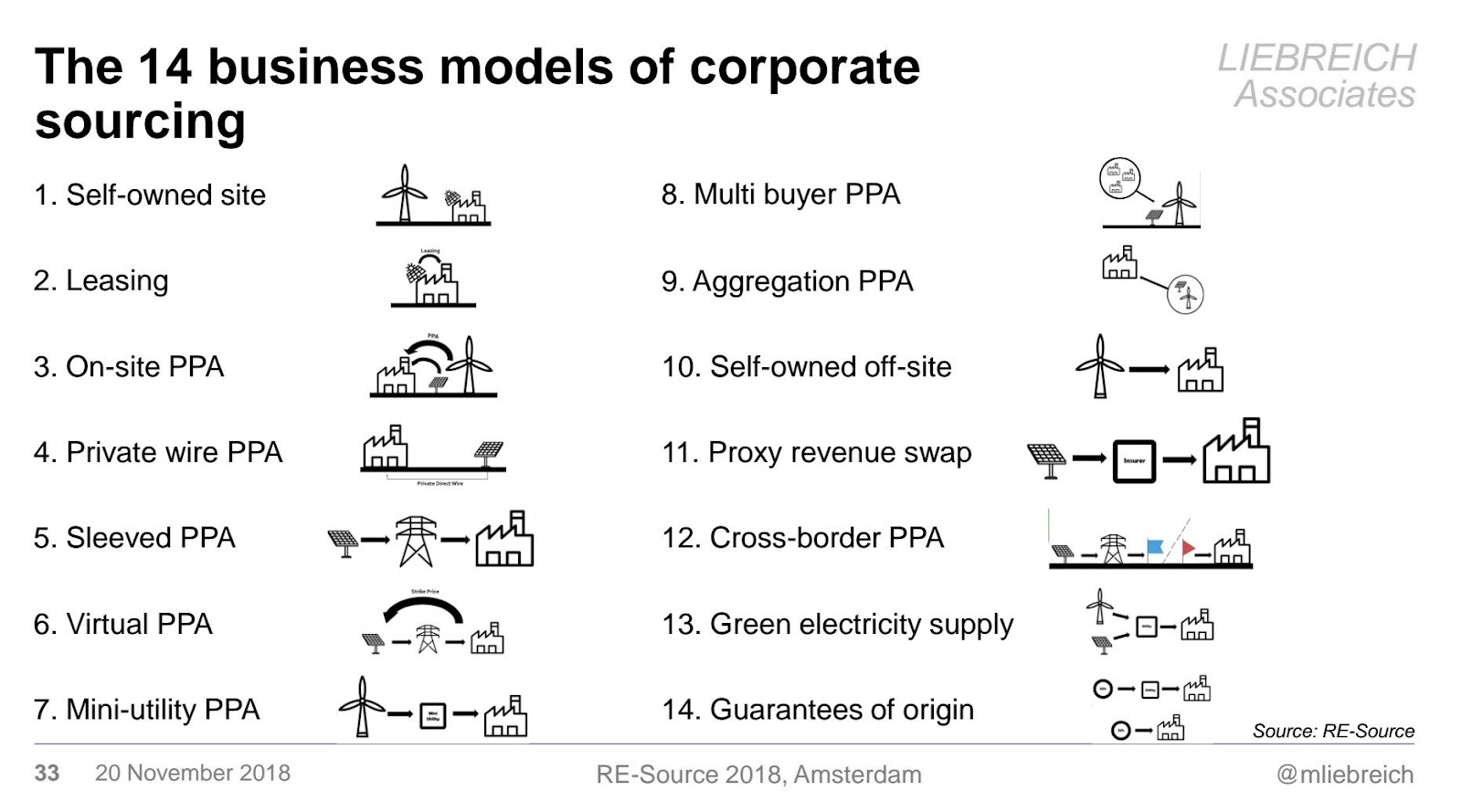
And as this diagram from Sonia Dunlop of RE-Source suggests, more you look at it, the more complicated it can get:
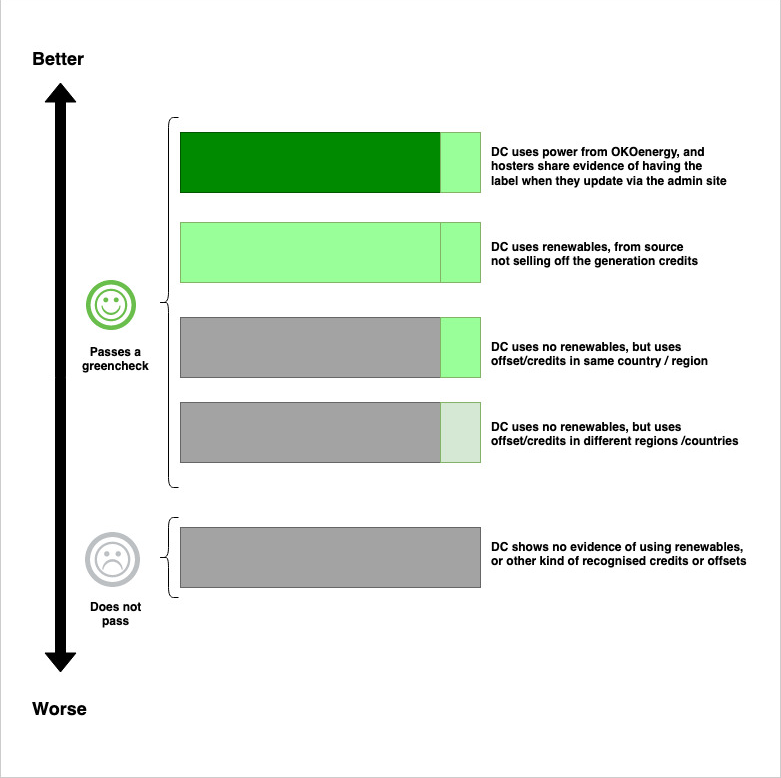
To save you needing to do an MSc in energy policy before you can say if a site is green or not, we’ve been sharing this draft diagram internally to give some idea what we mean when we say green power – which is what we look for when you check a website using the Green Check API, or use one of our browser addons.
How we do this
You might wonder how we do this – and we currently work this out by running a series of checks against the network for a given website, combined with some manual checks when organisations get in touch to be listed as green providers.
Earlier this year we open sourced the underlying code used in the platform to show make it possible to see how we do this in more detail, but in all these cases, we’ve relied on people signing into the green webfoundation admin site to update information about their infrastructure, which has created more friction than we’d like
So, we’re trying something new.
As an experiment, we’re trying out an approach that uses the architecture of the web itself to make it easier to declare this information we typically ask people to provide in our admin site, to make it possible to have verifiable, traceable claims of running on green power.
carbon.txt – robots.txt for renewable power
One of the things that helped search engines become such an integral part of the web we know is a convention known as robots.txt.
It made it easier for search engines to collate information about the content on a site, and let people build useful services on top of that data, by outlining what information you want search engines to index.
Inspired by this, and other .well-known approaches we’ve been looking at ways to make it easier to automatically update information about how a website is powered, without needing to sign into an admin site run by the Green Web Foundation, that we’re calling carbon.txt.
Rather than relying on someone in your organisation to sign into an admin website to add information to a database, you’d declare similar information in a carbon.txt file available on your own site, in an agreed-upon format
What specifically you’d put in is something we’re working on, and we have a site set up now, to help work this out, at carbontxt.org.
You’re invited to join the discussion there.
Why this might be better
We have a few goals in mind with this approach, and we know it’s early days, but these are some of the specific things we want to do with this:
- to reduce the need to store login data about users updating information about a site
- to make it possible to build more tooling beyond the green checking tools so far
- to make it possible to audit a digital supply chain, so you can verify claims of green power
- make it possible to point to structured, relevant information, related to carbon emissions
- to cover use cases we haven’t thought of yet
We’re actively looking for partners to work with on this – we think the web should be green, and if you think so too, please get in touch.