In an earlier post, Understanding trends at the layer below the internet stack, we looked at the “stack below the internet”, and learned that trends in economics of renewables make the idea of a fossil free internet both desirable and achievable. In this post, we’ll show how you might take ideas like demand curves and different ways to generate a commodity like electricity, and use them to help us think about the different ways to provide a commodity like computing.
First a recap of the last post
For those who haven’t read the last post in this series, the short version is as follows:
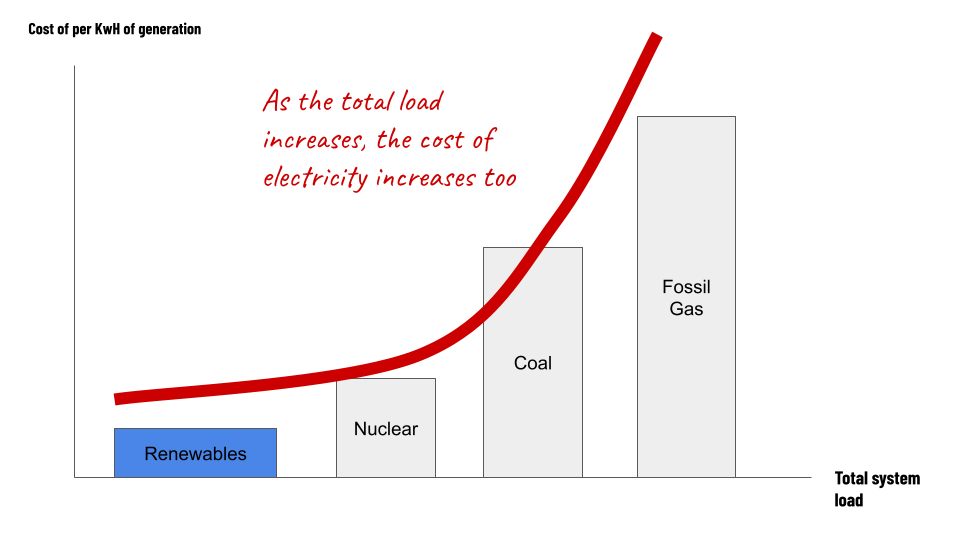
On an electricity grid, as the amount of demand for electricity climbs, so too does the cost per unit of electricity that people are able to sell their electricity for.
This means that some kinds of generation need to be running almost all the time and selling all power they generate, to ever have a hope of paying off the loans it took to build them. But it also means there are others that barely need to run at all in a given year, and they can still pay for themselves, because they only run when the cost of electricity is really high.
We can look at the properties of these different kinds of generation, as creating a kind of demand curve.
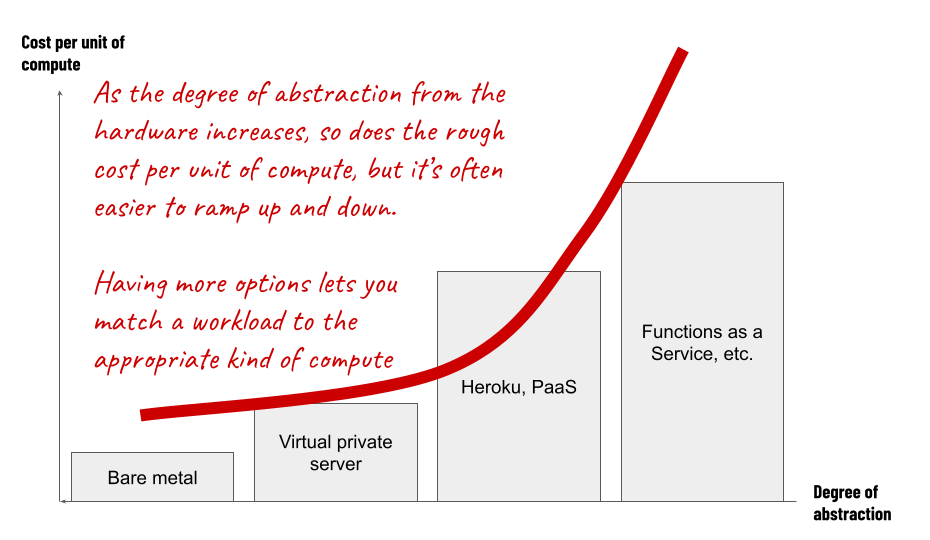
What this has to with computers and cloud – a demand curve for compute
This concept of a demand curve is useful when thinking about how we compose systems from different kinds of infrastructure services too.
Over the last few years, computing workloads themselves have become more portable, as people get better at packaging them up into easily deployable pieces of software, and abstracting them from the underlying hardware. This has made them more fungible.
This first happened as virtual machine images, and then more recently as containers, and in 2021, we now have a plethora of options from micro-kernels, micro-vms, and so on.
Let’s assume as an example, we have a relatively portable computing job that we want to run somewhere. It might be a WordPress website, or it might be a machine learning job we need to run on a regular basis. Because it doesn’t matter that much what it is, let’s just call it a workload, to represent that’s something we need to run, but one where we have some degree of freedom where we run it.
Matching the job to the infrastructure
Once we have a computing job that’s relatively portable, we are then able to make decisions about how we run it, and match the properties of that workload to the choice of digital infrastructure that fits it best.
To help us do this, it’s helpful to think about the things we might trade-off on when deciding where we run our workloads.
Cost per unit of compute
Unsurprisingly, the cost we’re prepared to pay per unit for anything is something we’re likely to make a deliberate decision about. In our case, we might think in terms of how much compute we expect to get for the money we pay – let’s call this our cost per unit of compute. It’s likely to change depending where or how we run it.
Degree of abstraction
Another thing to think about for our workload might be the degree of abstraction we are comfortable with. It helps here if we think of compute power like a fungible metered utility, the same way we think about electricity as one.
You might run the same workload on a range of different providers, who are all able to provide the computing power, but with different properties that make them a better or worse fit for it.
Let’s look at them in turn, like we did with the different forms of power generation.
Different ways to run a computing job
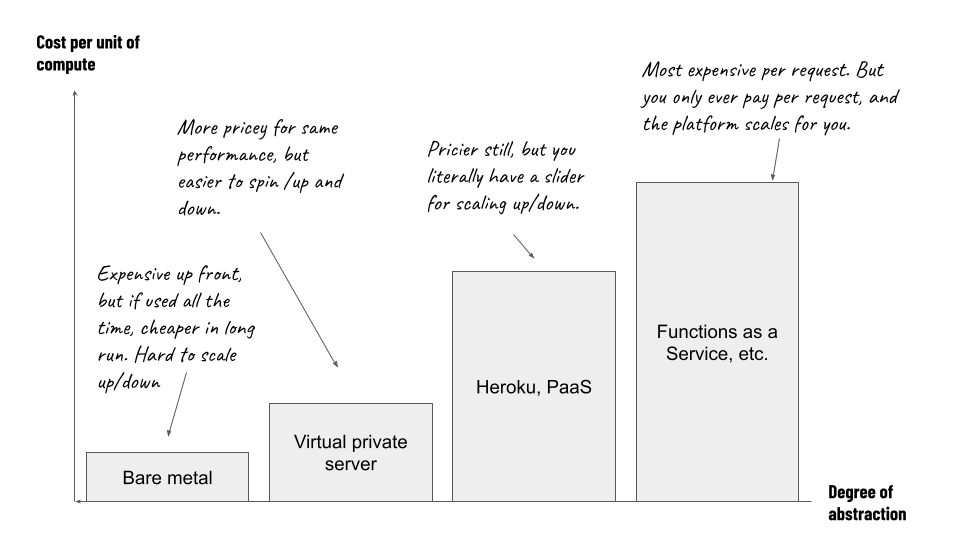
Bare metal – Low unit cost, less abstraction, harder to scale up and down
If we know we have a very predictable, but heavy compute workload that’s running almost constantly, we might make a choice to trade-off some of the ability to scale compute capacity up and down, as long as each unit of compute is relatively cheap – you might think of this like the current generation of nuclear power on the energy demand curve in the earlier blog post.
In our world of the internet, this might look like us using a bare metal server, where there is little to no abstraction of the workload from the underlying physical servers.
But this isn’t the only scenario that describes this set of conditions – some providers sell virtual machines, at a lower cost per unit, if you commit to paying to use them for an extended period of time.
In both cases, you’re committing to a set amount of use, on an annual or longer time frame. This is still a very common way that computing is paid for, and if any thought is given to how well a set up like this scales, it’s how well it handles an increase in required work before you need to buy another new server. We assume the server has to be running in order for there to be capacity to meet demand.
Virtual machines – Higher unit cost, more abstract, easier to scale
Another scenario might be where you have a workload where it’s harder to predict usage. You might not want to pay up-front for an entire server, or a year’s worth of use in advance, just to run a job that you know you might not be running 24 hours a day, 365 days a year.
In this scenario you might prefer to run virtual machines with a provider instead. On a per-unit-of-compute basis, you might pay a little more, but that is offset by the ability to switch it on or off more easily.
You likely still are responsible for some setup and configuration, but you might not need to lose sleep about being the poor soul who has to replace physical hardware if something breaks.
And if we compare to our earlier energy post, we might think of the properties here as something a bit like a coal fired power station compared to a nuclear one – where a generator is paying more per unit of electricity, but is able to ramp production up and down more easily.
Just like coal, virtual machines are now ubiquitous, but even in 2021, if you’re looking for virtual machines where all the energy used is matched by power coming from fossil free sources, there are fewer providers of this kind of compute than you’d think who will sell it at a more granular resolution than paying on per-month basis.
Managed platforms – Hosted kubernetes, or platform-as-a-service offerings like Heroku
Going further along the abstraction scale, rather than paying for a virtual machine that you set up yourself, you might accept a set of defaults provided by a platform which abstracts the underlying compute away from you even further.
Again, you’ll likely pay more per unit of compute, but the added abstraction makes it easier to ramp up and down. Also, increasing amounts of busy work that you might have done before is abstracted away too, and there is a greater degree of tolerance built into the platform to the underlying hardware failing.
The poster child of this kind of platform is a service called Heroku, but increasingly, an open source project called Kubernetes has grown to prominence as a basis for building many other more abstracted services like this.
Scaling down as well as scaling up
There are definitely benefits here. If you’re running services that are mainly used during office hours, then it’s likely they’re being used 40 hours out of 168 possible hours each week. This means that rather than paying for the three quarters of the time when they’re barely being used, you have the option of not running these machines.
Also, the same features that make a system more tolerant of hardware failure can make it handle scaling downwards as well as scaling upwards, giving you a degree of flexibility that you didn’t have before, about when and how you run a workload.
This means it’s increasingly common to pay for this on an hourly basis, and for it to be realistic to adjust the amount of computing capacity you’re paying for, on an hourly basis, when you’re working at this level of abstraction.
You don’t burn cycles needlessly, you don’t burn cash needlessly, and hopefully, it results in burning fewer fossil fuels too.
However, because these are often built on top of virtual machines themselves, you end up with even fewer providers to choose from – especially if you care about running them with cleaner energy. In many cases if you want this level of abstraction, you might need to compromise on who the underlying providers are, or be explicit about choosing a greener provider in the supply chain.
Functions as a service or serverless – even higher unit cost, even more abstract, scaling built in
Finally, if we’re prepared to abstract away the underlying devices even further, you can end up with a model where you basically pay per invocation of a given workload, rather than paying to reserve a bunch of machine time in which you can run that workload.
If you run a website, instead of paying to run a webserver continuously, and hope that it can handle enough of the incoming from users, you might pay on a per request basis, and rely on the platform to take care of ramping up resources, and then ramping them down again.
It may be the case that what compute do you end up consuming is even more expensive on a per-use basis than all the other options we’ve covered. But a bit like the gas turbines from our earlier energy example that we can start and stop easily, if you’re only ever paying for what you use, you can end up with very low total costs just because your total usage is so low – you’re no longer paying to leave idling computing processes running, waiting for input between requests on a website.
If you only have a single, minute-long compute job to run at midnight, you probably don’t want to keep that machine running the other 23 hours and 59 minutes every day if you can help it.
Visualising a demand curve for compute
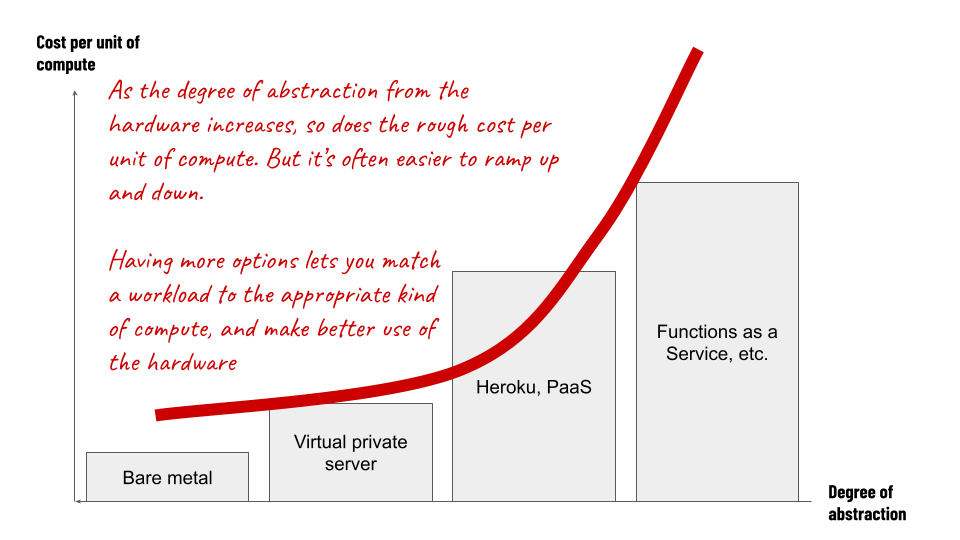
This is how I visualise the different ways you might run a single computing job these days – I picture a demand curve just like how we might picture one in the energy sector, and the myriad ways to generate electricity.
I hope it shows that some ideas from other domains can help us think differently about digital infrastructure – because once you start thinking of it like an essential utility our society is built on, you can start bringing to bear all kinds of other ideas.
What this has to do with a greener digital sector

Getting back to the subject of compute powered by green energy, if we know we are able to think independently about the kind of computing job we want to run, and where or how we want to run it, it allows for re-thinking what a datacentre should look like, or where we want to build reliability into any system we use.
One interesting example here would be the German company, Examesh.
They build datacentres into the base of wind turbines, to take advantage of power that would otherwise be wasted, or to use the energy jargon, curtailed.
We say energy is curtailed when it can’t be fed into the grid, and put to productive use – this often happens because there is no way to move the power to where a workload needs to be run, due to a local oversupply of power on the grid causing ‘congestion’ on the power lines.
But if you can move the workload to where the power is instead, you can change the economics, and the clean, variable power that would be wasted can be put to productive use instead. Better yet, if we’re able to make use of existing phsyical infrastructure like this, we don’t need to build another purpose-built datacentre building just to service those workloads.
This is a different model to the more common approach of building massive datacentres which stand apart from the rest of the built environment. And it’s partly made possible by us thinking about compute workloads as things we can run on different kinds of fungible sources of computing power – and realising that by matching them to different sources, we can optimise for cost, for carbon emissions, speed, and so on.
This isn’t the only idea from the power sector that can help us think differently about digital infrastructure, but I do think it’s useful one, and we’ll explore some more of these ideas in future posts.
To follow along, you can subscribe to our web feed with a feed reader, you can join our newsletter, or if you prefer, follow us on twitter at @greenwebfound.